Key Takeaways
1. Multimodal AI integrates diverse data types, revolutionizing video editing efficiency and precision.
2. Automated video analysis enables rapid identification and extraction of key moments from extensive video libraries.
3. Challenges such as privacy, resource demands, and AI’s alignment with human judgment remain important considerations for industry adoption.
4. Innovative models and strategic technology integrations drive industry advancement, paving the way for increasingly context-aware video editing tools.
Introduction to Multimodal AI in Video Editing
Multimodal AI is transforming the landscape of video editing by leveraging the power of data integration. Unlike traditional single-source methods, multimodal AI synchronizes information from text, audio, and visual streams, dramatically enhancing the process of moment identification in video content. With the rise of automated clipping software, professionals can streamline workflows and unleash creative potential without being bogged down by tedious manual editing.
The synchronization of multiple data sources increases efficiency and provides a holistic understanding of video content. For editors, this reduces the need for extensive manual scrubbing through footage, freeing valuable time for deeper, more creative storytelling.
The Evolution of Video Clipping Techniques
Once reliant on labor-intensive manual review, video editing has undergone a dramatic transformation. Historically, editors spent hours scanning entire timelines to pinpoint crucial scenes, relying on memory or inconsistent notes. The introduction of artificial intelligence into editing software marked a watershed moment. Early iterations offered basic object recognition and rudimentary scene detection. Today, multimodal AI systems excel at parsing complex content, recognizing objects and faces, and contextual cues like tone of voice, spoken keywords, and even scene sentiment.
Modern AI-powered editors can search through archives, extract the best moments in seconds, and recommend highlights for diverse use cases—broadcast news, social media snippets, or class lectures. As reported by CNET, these developments have changed the editor’s role from manual labor to creative curatorship, heralding a new age in visual storytelling.
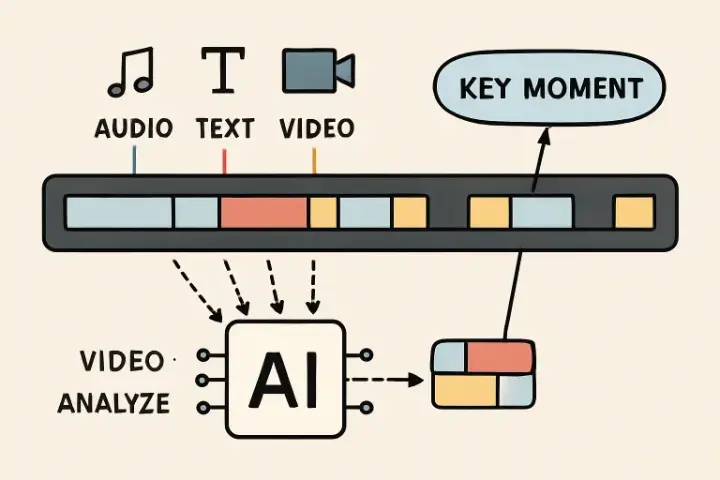
How Multimodal AI Enhances Video Clipping
Multimodal AI stands out by its ability to simultaneously analyze and interconnect information from different channels—spoken language, transcribed text, emojis, gestures, on-screen graphics, and more. By creating multiple metadata layers, advanced AI systems enable instant content tagging and smarter search functionalities. For example, a system might identify a critical basketball game moment by analyzing crowd reactions (audio), the scoreboard (visual), and commentator excitement (text and audio). This level of contextual awareness drives more precise, automated clip selection than ever before.
Generating this granular metadata allows editors to search footage with everyday language queries, such as “find every goal celebration where the audience cheered loudly.” This nuanced, comprehensive indexing approach unlocks powerful editing abilities for professionals and enthusiasts.
Benefits of Using Multimodal AI for Video Clipping
· Efficiency: AI-powered workflows drastically cut manual editing times, optimizing staff resources and delivering faster project turnarounds.
· Accuracy: The multi-layered context analysis provided by multimodal AI leads to more precise clip selection, minimizing human oversight or bias.
· Scalability: Automation allows organizations to manage ever-growing video libraries, enabling quick search and retrieval at any scale.
Challenges and Considerations
Despite its advantages, the implementation of multimodal AI presents notable challenges. Privacy concerns are at the forefront regarding sensitive or personally identifiable data within video and audio streams. Secure data management and robust ethical oversight are essential. In addition, the hardware and energy demands of high-level AI processing can be substantial, requiring significant infrastructure investments. Another key challenge is ensuring AI’s understanding and output remain aligned with human editorial standards—a task that occasionally requires oversight and manual correction.
Future Trends in Multimodal AI for Video Editing
The next wave of advancements in multimodal AI is expected to deliver even deeper contextual awareness and creative intelligence in editing. Cutting-edge models like VLAB are pioneering feature blending and adaptive pre-training, enabling video AI tools to interpret nuanced narrative cues and scene context more effectively than ever. Continued collaboration between academia, tech startups, and legacy media organizations will push boundaries, creating smarter, more intuitive video editing tools.
As AI performance improves and resource costs decrease, expect democratized access to high-quality video editing—empowering small teams and individuals to create compelling, professional-grade content with minimal effort.
Final Thoughts
Multimodal AI represents a paradigm shift in video editing, supercharging the speed, accuracy, and accessibility of content creation. By automating detailed moment identification and extraction, these systems let creators focus on storytelling rather than technical hurdles. As innovation accelerates, multimodal AI will further enhance digital media’s value, redefining industries and inspiring a new generation of video storytellers.
How Multimodal AI Is Changing the Way We Clip Video Moments